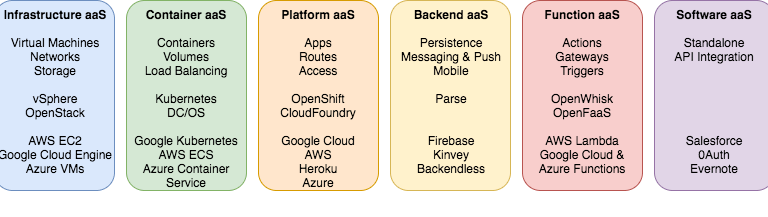
In der Welt von InfrastructurePlattformContainer/Software as a Service wird immer häufiger auch von Function as a Service (FaaS) gesprochen. Dabei ist das Konzept von FaaS für die meisten Cloud-Natives unter euch schon ein alter Hut.
FaaS wird leider sehr oft auch mit Serverless gleichgesetzt, was aber nicht ganz richtig ist wie wir in den nächsten Minuten sehen werden. Ich möchte mir mit euch anschauen woraus Serverless eigentlich besteht, warum FaaS != Serverless ist und für welche Anwendungsfälle Serverless eine interessante Wahl ist.

FaaS reiht sich zwischen Backend und Software as a Service ein. Unter FaaS allgemein kann man die Bereitstellung einer Plattform zum ausführen von Code verstehen ohne sich dabei Gedanken um die Infrastruktur machen zu müssen. Serverless hingegen ist ein Architekturansatz welcher auf mehrere Komponenten von Backend, Function und Software as a Service zurückgreift.
Serverless & seine Prinzipien
Serverless übersetzt steht für „ohne Server“, natürlich ist dies so nicht ganz richtig, denn Server hat man am Ende des Tages immer. Richtiger wäre es zu sagen „ich möchte mich um keine Server kümmern“, aber der Name wäre wohl etwas zu lang geworden 😉 Potes und Nair haben vor einigen Jahren das „serverless compute manifesto“ vorgestellt. Das „serverless compute manifesto“ umfasst folgende acht Punkte:
- Funktionen sind die Einheit die bereitgestellt und skaliert werde
- Keine Maschinen (Server), VMs, oder Container sind im Programmiermodell sichtbar
- Permanenter Speicher „lebt“ anderswo
- Skaliert pro Aufruf. Nutzer können die Kapazität weder Über- noch Unterprovisionieren
- Bezahle niemals für einen Leerlauf (keine kalten Server/Container oder deren Kosten)
- Implizit fehlertolerant, da Funktionen überall laufen können
- BYOC – Bring Your Own Code
- Metriken und Protokollierung sind ein universelles Recht
Im Grunde definiert das Manifest, dass es bei Serverless um die reine Funktionalität oder Funktion geht, und diese dann zur Verfügung steht, wenn diese benötigt wird. Alles andere (Rechenleistung, Speicher, Netzwerk) wird als gegeben vorausgesetzt, sodass im Betrieb allein die Funktionen und deren Zusammenspiel wichtig sind. Daher ist das Manifest in meinen Augen auch eher ein „Function as a Service Manifest“, denn Serverless ist mehr als nur isolierte Funktionen. Für die konkrete Entwicklung von Serverless orientierten Lösungen eignen sich daher die Prinzipien von Sbarski und Kroonenburg mehr. Diese sind praktikabler bzw. leichter zur erfassen und zu vermitteln. Darüber hinaus beschreiben sie den Gesamtkontext des Serverless deutlicher.
1. Verwende Compute Services nach Bedarf
Das erste Prinzip sollte euch bekannt vorkommen denn es steht als „Skaliert pro Aufruf“ auch im Manifest. Grundlegend sagt es aus, dass die Server-Kapazität bzw. Rechenleistung auch nur dann verwendet werden wenn sie gebraucht werden. Dies lässt sich natürlich schlecht mit klassischen Servern oder VMs realisieren, da hier das starten bis zu mehreren Minuten dauern kann. Fast alle Cloud Betreiber bieten daher entsprechende Services an. Die bekanntesten darunter sind AWS Lambda, Google Cloud Functions oder Azure Functions. Diese Services lassen sich auch als Function as a Service (FaaS) zusammenfassen und funktionieren im Grunde nach dem Prinzip, dass lediglich der nicht mehr als eine Funktion umfassende Code in den Service geladen wird. Die Cloud Plattformen bieten rund um ihre FaaS Lösung weitere Integrationen an wie bspw. Verbindungen zu Datenbanken, Blockspeichern oder Messaging Systemen.
2. Schreibe zustandslose Funktionen, die nur einem Zweck erfüllen
Wie die Bezeichnung „Function“ as a Service schon klar macht, geht es nicht darum, eine ganze Anwendung oder umfangreiche Code Segmente zu verwenden. Eine Funktion erfüllt dabei einen Zweck: Wenn eine Datei auf einen Speicher geladen wurde, erstelle einen Datenbankeintrag, schiebe eine Datei in den nächsten Service (wie Video Transcoding, Bilderkennung etc.), finde in der Datenbank den Bestellstatus, usw …
Wichtig ist hierbei auch die Funktionen zustandslos zu gestalten, denn sobald die Funktion mit ihrer Tätigkeit/Berechnung durch ist, wird diese wieder „heruntergefahren“ bzw. deaktiviert. Anders als eine VM behält diese dabei nicht ihren Speicher, dieser wird vollständig verworfen. Eine Frage die hierbei gerne aufgeworfen wird ist „Wie groß ist denn dann eine Funktion?“. Eine Wissenschaftlich validierte Antwort gibt es darauf wohl nicht, aber der Großteil bewegt sich zwischen 10 und 100 Zeilen Code. Was man bei diesem Prinzip nicht falsch verstehen sollte ist, nicht jeden einzelnen Prozessschritt in eine Funktion auszulagern auch wenn sich hier die Clean Coder vielleicht wiederfinden würden. Dies würde zu einer unnötigen und unüberschaubaren Komplexität führen.
3. Designe push basierte, Event getriebene Lösungen
Ein Schlüssel damit Serverless reibungslos funktioniert ist die push basierte Gestaltung des Systems. Das beutetet, dass jeder Prozessschritt den nächsten anstößt. Man spricht hierbei auch von Events. Im Gegensatz zu pull basierten Systemen, in denen die Ressourcen quasi selbst entscheiden in welchem Umfang sie auf Events reagieren und damit Ressourcen allokieren, müssen in den push basierten Systemen die einzelnen Komponenten oder Services den Anfragen entsprechend skalieren. Was wiederum auf die Kerneigenschaft von Serverless verweist. Dies lässt sich bspw. mit klassischen Message Queue System schlecht realisieren. Ein Apache Kafka setzt auf ein Public & Subscribe Model, das bedeutet, dass zwar ein Push zum Message Broker erfolgt, die Message aber dort abgeholt also gepullt werden muss. Es gibt natürlich kreative Köpfe die alle paar Sekunden oder Minuten eine Function starten um die Queue zu pullen, dies zeigt aber ein schlechtes Systemdesign oder Missverständnis von Serverless.
4. Entwickle umfangreiche Frontends
Computer und Übertragungsnetze werden immer Leistungsfähiger. Daher können Frontends mehr als nur statische Inhalte anzeigen und sind in der Lage selbst umfangreichere Teile der Business Logik abzudecken. Diese Entwicklung kommt auch dem Serverless zugute, sodass die Frontends direkt (meistens über ein API Gateway) mit den relevanten Funktionen sprechen. Dies gilt natürlich nicht für alles, bspw. aus Sicherheits- oder Datenschutzgründen. Angenommen ihr habt eine Plattform auf der Zahlungen getätigt werden, dann sollten die Bezahlvorgänge im Backend oder über einen Serviceprovider geschehen. Mittels moderneren Schnittstellen wie einem GraphQL müssen auch nicht mehrere REST abfragen ausgeführt werden um einen halbwegs komplexen Datenstand abzurufen bzw. es verhindert das eine Web oder Mobile Anwendung zu viel mit dem Backend am kommunizieren ist.
5. Nutze Services von Drittanbietern
Ein weiterer spannender Punkt der nicht im Manifest aufgegriffen wird ist die Nutzung weiterer Services, nicht nur diese der Cloud Betreiber sondern auch von Drittanbietern. Die Schlüsselaussage dabei ist: Du musst dich um keinen Betrieb irgendeiner Infrastruktur kümmern. Lediglich die Funktionalität und etwas Netzwerkverwaltung bleibt am Ende übrig. Die Cloudbetreiber bieten eine große Auswahl an Services, die genutzt werden können. Von Datenbanken und Storage, Messaging und Serverless Hosting Optionen bis hin zu Machine Learning, Transcoding, Translateing Services ist eine breite Auswahl vorhanden. Auf dem Markt entwickeln sich aber auch sehr starke Speziallösungen insbesondere im Identity und Access Management gibt es spannende Produkte bspw. von Auth0, oder auch Firebase welches fast schon mehr als nur eine Backend as a Service ist und Authentifizierung und weitere Funktionalitäten zur Verfügung stellt.
Die Nutzung und Kombination von unabhängigen Services sind ein Kernelement von Serverless. Dadurch ist eine sehr schnelle Entwicklung und ein weniger aufwendiger Betrieb erst möglich.
Function as a Services != Serverless
Wie ich schon einführend gezeigt habe gibt es einen gewissen unterschied zwischen FaaS und Serverless. Wenn über FaaS gesprochen wird fallen meistens Begriffe wie AWS Lambda, Google Cloud Functions, OpenWhisk und OpenFaas. Kurz gesagt, ist FaaS die Plattform die es mir ermöglicht funktionsorientierten Code auf einem System zu betreiben und durch andere Services ansprechen zu lassen.
Serverless hingegen ist ein Architekturansatz oder mehrere Prinzipien zur Realisierung von Lösungen bei denen die eigene Verwaltung und der Betrieb eine untergeordnete Rolle spielt. Serverless greift jedoch auf „managed“ Services zu bspw. eine Firebase oder DynamoDB. Mike Roberts hat dies einmal sehr gut zusammengefasst.
„Serverless architectures are application designs that incorporate third-party “Backend as a Service” (BaaS) services, and/or that include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform.“
Das nachfolgende Bild zeigt noch mal sehr grob den Kontext von Serverless. FaaS ist ein Bestandteil zur Realisierung von Serverless, sowie viele weitere, vom Cloudanbieter verwaltete, Produkte/Services dies auch sein können. Allerdings sind die Virtuellen Maschinen (EC2) welche IaaS sind kein Bestandteil von Serverless, da man sich hier um das Betriebsystem, installierte Systemkomponenten (Webserver, Datenbank Engines etc.) und Updates kümmern muss.

Anwendungsgebiete für Serverless
Wir haben uns bisher angeschaut was FaaS und Serverless ausmacht und was die Unterschiede sind. Wir kennen jetzt den Kontext von Serverless und was in dessen Rahmen möglich ist. Bleibt also die große Frage: Was macht man nun damit?
API Proxy für Altsysteme
Vor allem in alten und großen Unternehmen hat die IT mit schwerfälligen Altsystemen zu tun. Diese bieten oft massive APIs an und werden nach Möglichkeit so gut wie nicht angefasst. Serverless kann hier in Kombination mit einem API Gateway eine Abstraktionsebene schaffen und nach außen hin eine einfache REST API bereitstellen. Die Komplexität zwischen REST- und alt-API wird in der Funktion untergebracht. Dadurch können auch alte Systeme neueren System einfacher zugänglich gemacht werden. Die Funktionen überführen dabei oft die Daten von einem Datenformat in ein anderes, passen die Transcodierung an oder reichern die Anfrage um weitere Informationen an.

Daten Manipulation
Einhergehen mit dem vorherigen Beispiel geht die Datenmanipulation, daher hier nur kurz aufgegriffen. Serverless eignet sich ausgezeichnet zum Verschieben, Manipulieren, Transcodieren und Aggregieren von Daten (JSON, XML, Bilder, usw.). Aus einem architektonischen Standpunkt heraus kann dies zum “Compute as Glue”, also quasi als Klebstoff zwischen mehreren Systemkomponenten einsortiert werden. In manchen Fällen kann auch schon von ETL (extract, transform, load) gesprochen werden.
Serverless Backend
Wenn man Serverless vollumfänglich einsetzt spricht man vom Serverless Backend oder auch “Compute as a Backend” Architektur.
Das bedeutet: Unter Anwendung aller Serverless Prinzipien baue ich eine Applikation bei der ich mich um keine Server kümmern muss sondern nur um die reine Funktionalität.
Das nachfolgende Bild soll dies Visualisieren. Mit gelbem Text versehen sind die Services innerhalb eines Cloud Providers, während mit schwarzem Text andere Services gekennzeichnet sind. Die Anwendung ist dabei grob wie folgt Konzipiert.
- Beim Aufruf einer URL wird zunächst über Cloudfront die statische Website aus dem S3 Bucket ausgeliefert.
- Die Webseite Authentifiziert und Autorisiert den User über Auth0, einen Service Provider für Authentifizierung.
- Darauf hin werden Daten aus der Echtzeitdatenbank Firebase geladen und dem User angezeigt.
- Wenn dieser nun bspw. sein Profilbild anpasst wird dies über das API Gateway an eine Lambda Funktion übergeben, die das Bild im S3 hinterlegt (linker Lambda).
- Daten bzw. Informationsanpassung werden direkt vom Frontend in die Firebase geschrieben.
- Wenn der User jedoch bspw. einen Bezahlvorgang anstößt wird dies über eine Lambda Funktion abgewickelt und der neue Status wie ein Abonnement in die Firebase zurück geschrieben.
- Alle Daten werden über ein Lambda in eine Queue (SQS) eingespielt und von einer Lambda Funktion in Redshift als DWH Lösung eingespielt.
- Eine weitere Lambda Funktion greift Metriken, Logs und Meta Daten ab und schreibt diese in Elastic Cloud zur Visualisierung, Alerting und Monitoring der Anwendung.

Dies ist ein recht simples Beispiel welches für viele Use Cases eingesetzt werden kann. Die Komplexität nimmt ab diesem Zeitpunkt mit jeder Anforderung zu. Unabhängig wie groß das System am Ende wird, bezahlt man trotzdem nur für das, was benutzt wird. Während es gleichzeitig quasi grenzenlos Skalieren kann.
Zu guter letzt möchte ich noch drei sehr schlanke und interessante Anwendungsfälle ansprechen.
- Zum einen können die meisten FaaS Provider Funktionen schedulen sodass diese regelmäßig oder zu bestimmten Zeitpunkten ausgeführt werden.
- Dadurch könnte man bspw. Datenbanken aufräumen, Abrechnungen anstoßen oder Daten in einen Langfristigen Speicher überführen.
- Mit der Zunahme von Chatbots und Sprachassistenten ist die Relevanz von FaaS noch einmal angestiegen, da hierdurch einfach und flexibel einzelne Funktionen angesprochen werden können. Das erlaubt es den Entwicklern kostengünstige eigene Entwicklungen zu implementieren.
- Auch wenn REST Schnittstellen erst in den letzten 3-4 Jahren wirklich in Mode gekommen sind gibt es mittlerweile einen noch spannenderen Weg, Daten aus dem Backend zu ziehen bzw. zu manipulieren: GraphQL. GraphQL ist eine sehr einfache Query Sprache die auf einem Server oder Serverless ausgeführt werden kann und eine oder mehrere Datenquellen anspricht. Das interessante daran ist, dass bei komplexen Abfragen nur eine Query geschickt werden muss (die auch noch sehr einfach ist), während man im REST mehrere Abfragen kombinieren muss um das richtige Ergebnis zu erzielen.
Nicht desto trotz hat Serverless natürlich auch einige tradeoffs. Systeme die kontinuierlich unter hoher Last stehen, sehr viel Rechenleistung benötigen oder bei denen es auf jede Millisekunde ankommt werden in einem Serverless Umfeld nicht glücklich.
Abschließen kann ich nur sagen, dass Serverless eine großartige Chance bietet aus dem Nichts, schnelle, günstige und flexible Systeme zu bauen die schon per default keine Skallierungsgrenzen kennen. Gerade wenn man neue Ideen hat lassen sich diese hierüber einfach realisieren und testen. Auch nach “Lift und Shift” Migrationen, also dem einfachen überführen von OnPremise gehosteten Applikationen auf einen Cloud Provider, kann Serverless die Brücke zwischen “alter” und neuer Welt schlagen. Spannend ist außerdem die Entwicklung im Opensource Umfeld, wo schon einige interessante Projekte laufen die bei der Erstellung und dem Verwalten von Serverless Applikationen helfen.